اخیراً مدل هوش مصنوعی Minimax M2.5 معرفی شد و حسابی در دنیای تکنولوژی سر و صدا به پا کرد. این مدل خفن، سریع و ارزان است و در برنامهنویسی فوقالعاده عمل میکند. اما سوال اینجاست: چگونه آموزش دیده که با هزینهای بسیار کمتر، میتواند با مدلهای غولی مثل Claude Opus رقابت کند؟
تیم توسعهدهنده Minimax یک مقاله فنی عالی درباره این موضوع منتشر کرده است. اما یک مشکل کوچک وجود دارد: متن مقاله به شدت سنگین و پر از اصطلاحات آکادمیک است!
من آن مقاله را چندین بار خواندم، نکات گنگ آن را برای خودم حلاجی کردم و حالا میخواهم چکیده و مفهوم اصلی آن را به سادهترین شکل ممکن برای شما توضیح دهم.
خب، مقدمهچینی کافی است؛ بریم سر اصل مطلب!
مشکل اصلی چیست؟
مشکل اصلی که تیم مینیمکس سعی در حل آن داشت، این بود: چگونه میتوانیم یادگیری تقویتی (RL) را در مقیاس بسیار بزرگ اجرا کنیم تا یک مدل زبانی (LLM) به یک “ایجنت” (Agent) عالی تبدیل شود؟
ایجنتها (نمایندههای هوشمند) فقط برای این ساخته نشدهاند که به یک سوال شما پاسخ تککلمهای بدهند. یک مدل زبانی که میخواهد ایجنت خوبی باشد، باید یاد بگیرد که چگونه در محیطهای پیچیده تصمیمگیری کند، از ابزارها (Tools) استفاده کند، کانتکستهای طولانی را مدیریت کند و در حین انجام وظایف، قدم به قدم پیش برود.
آموزش مدلها برای تبدیل شدن به ایجنتهای خوب، چالشهای زیادی دارد. تیم مینیمکس به این چالشها میگوید «مثلث غیرممکن».
مثلث غیرممکن (The Impossible Triangle)
- توان عملیاتی سیستم (System Throughput): ما باید حجم عظیمی از دادههای آموزشی را خیلی سریع پردازش کنیم.
- پایداری آموزش (Training Stability): فرآیند آموزش باید به یک ثبات برسد و نمودارهای آن دیوانهوار نوسان نکنند.
- انعطافپذیری ایجنت (Agent Flexibility): ایجنت باید بتواند در طیف گستردهای از وظایف مختلف، خوب عمل کند.
«داربست» (Scaffold) چیست؟
کاربران، ایجنتهای هوش مصنوعی را در محیطهای مختلفی اجرا میکنند؛ مثل محیطهای چند-ایجنتی، محیطهای دارای حافظه، یا سندباکسهای برنامهنویسی. مدل هوش مصنوعی باید بتواند در تمام این محیطها به خوبی کار کند.
سوال: این کلمه “داربست یا Scaffold” که زیاد میشنویم یعنی چه؟در اینجا، داربست (Scaffold) به یک سیستم خارجی یا پوستهای گفته میشود که دورِ مدل زبانیِ پایه قرار میگیرد و قوانینی را تعریف میکند که آن مدل چگونه به عنوان یک ایجنت عمل کند.
یک مثال ساده: مدل Claude Opus یک هوش مصنوعی خام و آموزشدیده است. اما Claude Code یک “داربست” است که از Opus برای برنامهنویسی استفاده میکند. این داربست است که ابزارها، پرامپتها و درخواستهای API را مدیریت میکند.
آشنایی با کوره آهنگری: فریمورک Forge!
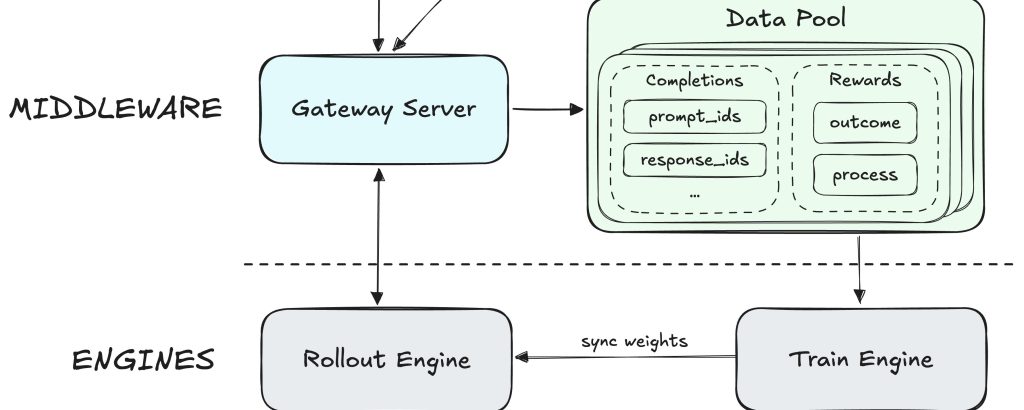
Forge (به معنی کوره یا جعلکردن) نام فریمورک اختصاصی مینیمکس است که برای حل همان “مثلث غیرممکن” ساخته شده است.
این فریمورک به این سوال پاسخ میدهد: “چگونه ایجنتهای پایداری آموزش دهیم که در انواع داربستها خوب کار کنند و بتوانند از حجم عظیم دادهها چیزی یاد بگیرند؟”
معماری Forge از ۳ بخش اصلی تشکیل شده است:
- سمت ایجنت (The Agent Side): کدهای خارجی که تصمیم میگیرند چه کاری انجام شود. (مدیریت کانتکست، استفاده از ابزارها و ایجاد مسیرها).
- لایه میانی (Middleware Side): یک رابط نامرئی که تمام درخواستهای ارسالی به مدل زبانی را رهگیری کرده و دادههای حاصل را در یک “استخر داده” ذخیره میکند.
- سمت موتور (Engine Side): جایی که موتور مدل زبانی و موتور آموزش قرار دارد. اینجا توکنها تولید میشوند و وزنهای مدل آپدیت میشوند.
این ۳ لایه چگونه با هم کار میکنند؟
- ایجنت یک درخواست به LLM میفرستد.
- این درخواست از لایه میانی عبور میکند.
- لایه میانی درخواست را به موتور استنتاج میدهد تا متن (توکن) تولید شود.
- در همین حین و در سکوت کامل، لایه میانی تمام این مکالمات را در یک “استخر داده” جمعآوری میکند.
- موتور LLM توکنها را میسازد و از طریق لایه میانی به ایجنت برمیگرداند.
- در نهایت، موتور آموزش در زمان مناسب، این دادههای ذخیره شده در استخر را برمیدارد و مدل را آموزش (آپدیت) میدهد.
چرا این معماری انقدر خاص است؟ (جادوی جداسازی)
بخش ویژه این معماری، همان لایه میانی (Middleware) است. سیستمهای دیگر مستقیماً ایجنت را به موتور آموزش وصل میکنند. اما مینیمکس با این لایه میانی، فرآیند تولید متن را از فرآیند آموزش جدا (Decouple) کرده است.
به لطف این جداسازی:
- ایجنت میتواند بدون معطلی به تولید مسیرها و مکالمات خود ادامه دهد.
- موتور آموزش هر وقت بخواهد دادهها را از استخر داده برمیدارد.
- منطق ایجنت از منطق آموزش کاملا مستقل میشود.
ترفندهای آموزشی مدل MiniMax
۱. آموزش ترکیبی (Mixed Training)
چگونه مطمئن میشوند مدل در همه چیز خوب است؟ آنها مدل را به جای اینکه یکییکی در محیطهای مختلف آموزش دهند، همزمان روی وظایف استدلالی، پرسشوتاسخ و وظایف ایجنتی آموزش میدهند. این کار باعث میشود یادگیری یک مهارت، باعث افت کیفیت مهارت دیگر نشود.
۲. پاداشها در یادگیری تقویتی (Rewards)
محیط تعیین میکند که ایجنت چقدر خوب عمل کرده و به آن پاداش میدهد. مینیمکس از چند ترفند جالب برای پاداش دادن استفاده میکند:
- پاداش مرحلهای: به جای اینکه فقط در پایان کار پاداش دهند، در وسط مسیر هم اگر ایجنت اشتباه کند (مثلاً ابزاری را اشتباه فراخوانی کند) جریمه میشود.
- پاداش سرعت تکمیل: مدل نهتنها برای درست انجام دادن کار پاداش میگیرد، بلکه برای سریع انجام دادن آن هم تشویق میشود! این باعث میشود مدل یاد بگیرد ابزارها را به صورت موازی اجرا کند نه پشت سر هم.
- پاداش آیندهنگر (Reward-to-go): هر اقدام ایجنت در یک مرحله، مجموع پاداشهای مراحل بعدی را دریافت میکند. این کار به مدل کمک میکند بفهمد دقیقاً کدام تصمیمش باعث موفقیت نهایی شده است.
بخشهای پیشرفته معماری (برای خورههای تکنولوژی!)
در این قسمت ۳ تکنیک بهینهسازی که مینیمکس برای افزایش سرعت استفاده کرده را خیلی ساده بررسی میکنیم:
۱. صف پنجرهای (Windowed FIFO)
تصور کنید ایجنت در حال اجرای وظایف مختلف است. بعضی کارها در دو مرحله تمام میشوند، اما بعضی دیگر بسیار پیچیدهاند و مکالمه بین ایجنت و LLM طولانی میشود.
برای اینکه کارهای طولانی جلوی پردازش را نگیرند، از سیستم “پنجره متحرک” استفاده میشود. در یک پنجره مشخص (مثلاً ۸ تسک همزمان)، کارها میتوانند بدون ترتیب خاصی تمام شوند، اما تا زمانی که کارهای کُند (stragglers) تمام نشوند، پنجره به جلو حرکت نمیکند. این کار باعث تعادل بین سرعت پردازش و یادگیری وظایف سخت/آسان میشود.
۲. ادغام درخت پیشوند (Prefix Tree Merging)
در مکالمات چندمرحلهای، پیامهای قبلی مدام تکرار و به پرامپت جدید اضافه میشوند. این یعنی کلمات ابتدایی در دهها مرحله کاملاً یکسان هستند.
به جای اینکه سیستم هر بار این بخشهای تکراری را از اول پردازش کند، بخشهای مشترک را ادغام کرده و فقط یکبار محاسبه میکند. مینیمکس گزارش داده که این کار سرعت آموزش را تا ۴۰ برابر افزایش داده است!
۳. رمزگشایی گمانهزن با پیشبینی چند توکن (Speculative Decoding with MTP)
تولید کلمات در هوش مصنوعی یکییکی انجام میشود و این کار کُندی است. معمولاً از یک مدل کوچکتر (مدل پیشنویس) استفاده میکنند تا چند کلمه بعدی را حدس بزند و مدل اصلی فقط آنها را تایید کند.
اما در یادگیری تقویتی، وزنهای مدل اصلی مدام در حال تغییر است و حدسهای مدلِ پیشنویس بعد از مدتی کاملا اشتباه از آب در میآید.
راهحل مینیمکس؟ استفاده از هدهای پیشبینی چند توکن (MTP). در اینجا مدل پیشنویس جداگانهای وجود ندارد؛ بلکه خود مدل اصلی دارای لایههای اضافهای است که میتواند همزمان ۲ تا ۳ توکن بعدی را پیشبینی کند. چون این بخش در دل خود مدل است، با تغییر وزنهای مدل، این بخش هم آپدیت میشود و دقتش پایین نمیآید.
جمعبندی: درسهایی که از Forge گرفتیم
اگر بخواهیم کل این مقاله را در چند جمله کلیدی برای برنامهنویسان و علاقهمندان به هوش مصنوعی خلاصه کنیم:
- جداسازی (Decoupling) عالی است: جدا کردن فرآیند تولید متن از فرآیند آموزش، کلید مقیاسپذیری است.
- پردازش ناهمگام (Async) جواب میدهد.
- ترکیب محیطهای آموزشی باعث ساخت مدلهای جامعتری میشود.
- پاداشهای میانی (Intermediate rewards) برای آموزش ایجنتها بسیار بهتر از پاداشهای صرفا نهایی هستند.
- میانافزارها (Middlewares) که در دهه ۶۰ میلادی اختراع شدند، هنوز هم شاهکارند!
- ساختمان داده و الگوریتم (DSA) نمرده است! (استفاده از درختها و صفها هنوز هم جان فریمورکهای بزرگ است).
اگر تا به حال مدل Minimax M2.5 را تست نکردهاید، پیشنهاد میکنم حتماً آن را بررسی کنید. سرعت بالا و توانایی کدنویسی آن با توجه به هزینه پایینی که دارد، واقعاً شگفتانگیز است.
(شما در پروژههای خود از چه مدل هوش مصنوعی استفاده میکنید؟ نظرتان را در کامنتها برایم بنویسید!)